Search is no longer just keyword matching. Modern systems combine dense vectors, retrieval strategies, and large models to deliver context-aware responses to users and downstream workflows. This article walks through AI-driven search algorithms end-to-end: why they matter, how to design them, platform choices, engineering trade-offs, and practical rollouts for teams that need reliable, scalable automation.
Why AI-driven search algorithms matter
Imagine a customer support agent sifting through a million documents to answer a question. Traditional boolean queries find documents that contain the words, but they miss paraphrases, context, or subtle intent. AI-driven search algorithms convert content and queries into vector representations, rank relevance with learned models, and optionally synthesize concise answers.
For beginners, think of the shift as moving from asking a librarian to find books that contain a phrase to asking a subject-matter expert to summarize the best passages and paraphrase answers in plain language. For product teams, that means faster time-to-value and higher user satisfaction. For engineers, it means new infrastructure—vector databases, embedding pipelines, and model-serving layers—plus tight observability to keep results trustworthy.
Key components and how they fit together
Core components
- Ingest pipeline: text normalization, chunking, metadata extraction, and embedding generation.
- Vector index / search layer: approximate nearest neighbor (ANN) engine to store and query vectors.
- Retrieval strategy: pure vector search, hybrid (vector + lexical) search, filtering by metadata.
- Ranking and re-ranking: lightweight learned rankers or cross-encoders to refine top results.
- Generation/answering layer: optional LLM-based synthesizer that uses retrieved passages (retrieval-augmented generation).
- Monitoring and governance: query telemetry, quality metrics, explainability, and access control.
Common technology choices
Open-source building blocks include FAISS for ANN, Milvus and Weaviate as vector databases, and Elasticsearch/OpenSearch for hybrid search. Managed vector services like Pinecone, Zilliz Cloud (Milvus), and proprietary offerings from cloud vendors accelerate adoption. For model inference and re-ranking, teams pick from hosted LLMs or self-hosted stacks using Triton, Ray Serve, or BentoML. Frameworks such as LangChain, LlamaIndex, and deepset Haystack glue retrieval and generation steps into reproducible pipelines.
Architecture patterns and integration
There is no one-size-fits-all architecture. The right pattern depends on latency requirements, query volume, data freshness, and control needs. Below are practical patterns and the trade-offs each implies.
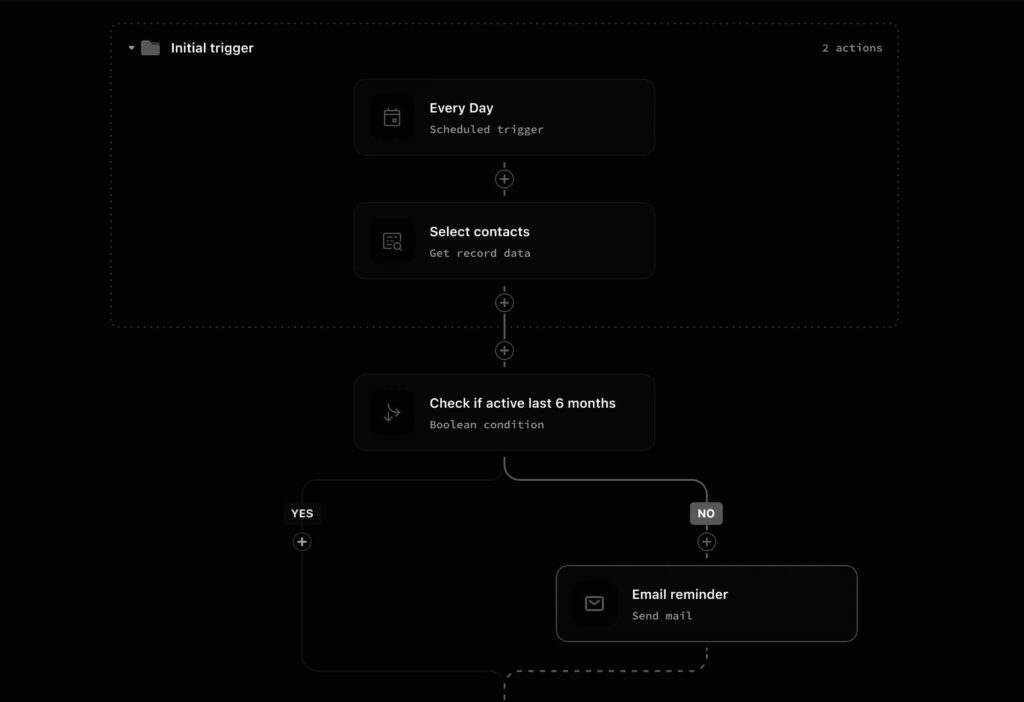
Synchronous API with inline retrieval
Best for interactive applications that want single-round responses. The client issues a query, the API performs a vector lookup, optionally re-ranks, and returns a response or a synthesized answer. Target latencies range from 50ms for simple vector lookups to 300–800ms when invoking a large language model. Challenges include managing request spikes and ensuring the model doesn’t introduce hallucinations.
Asynchronous or event-driven retrieval
For high-throughput pipelines (batch analytics, long-running searches), an event-driven approach uses message brokers like Kafka or SQS. Ingest and embedding jobs are decoupled from query-time retrieval. This pattern is more resilient to load and supports incremental indexing, but it increases overall complexity and introduces eventual consistency in search results.
Hybrid architectures
Combine a fast, cached lexical layer (Elasticsearch/OpenSearch) for low-latency filtering with a vector index for semantic relevance. Use a fast lightweight model for re-ranking in the hot path and a heavier generator in the background to produce richer answers for user-facing sessions. This balances cost and latency while improving relevance.
Agent frameworks vs pipeline composition
Agent frameworks (multi-step reasoners that call tools) provide flexible workflows for complex tasks but can be monolithic and harder to audit. Modular pipelines (embeddings → retrieval → rank → generate) are easier to test, monitor, and scale independently. If reproducibility and governance are priorities, favor modular pipelines with well-defined interfaces.
Implementation playbook for engineering teams
Below is a step-by-step playbook to build a production-grade AI-driven search algorithms system without code snippets—only decisions and operations to follow.
- Clarify objectives and SLOs: Define latency SLO (e.g., p95
- Map data and privacy constraints: Classify documents for PII, set retention rules, and specify regions for data residency if required by regulation like the EU AI Act.
- Choose embedding models: Start with off-the-shelf embed models for semantic search. Consider using a model family consistent with your generation layer to reduce representation mismatch. If you need on-premise control, consider open models, otherwise use hosted APIs for speed of deployment.
- Select an index: For low ops, pick a managed vector DB. For full control and custom ANN tuning, choose FAISS or Milvus on Kubernetes.
- Design the API contract: Offer both synchronous and async endpoints. Provide parameters for top-k, filters, re-ranking toggles, and confidence thresholds. Return provenance data and source citations with each result.
- Implement observability: Capture query latencies, index hit rates, re-rank times, answer confidence, and user feedback. Surface drift indicators for embeddings and concept coverage gaps.
- Establish governance: Automate redaction for sensitive fields, maintain access logs, and require human review flows for high-risk responses.
- Rollout incrementally: Start with an internal beta, tune the retrieval and rankers using A/B tests, then widen to production with careful rollback plans.
Deployment, scaling, and cost considerations
Key metrics to monitor:
- Latency (p50, p95, p99) of vector lookup, re-ranking, and generation.
- Throughput in QPS and batch sizes when batching embeddings or re-ranking calls.
- Index size and memory footprint (ANN indices are memory-heavy and often require SSD for persistence).
- Cost-per-query considering embedding generation, ANN compute, and LLM inference.
Managed services simplify capacity planning and provide auto-scaling for the vector layer, but they can be expensive at scale and limit customization of ANN parameters. Self-hosted clusters on Kubernetes give full control—important if you need specialized hardware for the Megatron-Turing model family or GPU-accelerated inference—but introduce operational overhead for upgrades, backups, and multi-region replication.
Observability, reliability, and failure modes
Practical systems track both system-level and relevance-level signals. System signals include CPU/GPU utilization, memory pressure, latency, and queue lengths. Relevance signals require human-in-the-loop telemetry: click-through-rate on answers, user correction rates, and explicit feedback. Additional signals include embedding drift (statistical shift in vector distributions) and stale index detection.
Common failure modes:
- Hallucination in generated answers despite correct retrieval—mitigate with conservative confidence thresholds and source citations.
- Index staleness from delayed ingestion—use incremental indexing and monitor freshness metrics.
- Query spikes causing increased latency—implement rate limits, graceful degradation to cached or lexical-only results, and autoscaling policies.
Security, compliance, and governance
Protect data at rest and in transit; encrypt vector stores and control key management. Apply role-based access to search APIs and use field-level redaction for regulated data. Maintain audit logs for queries and returned sources. For legal and compliance teams, keep model cards, data lineage, and decision records. If you use third-party hosted models or assistants—such as Claude AI-powered assistants—ensure contractual controls about data use and retention and understand the model provider’s data policies.
Vendor and model comparisons
When evaluating providers, compare on these axes: latency, throughput, index consistency, query API flexibility, embedding model choice, cost, and compliance. Managed vector databases (Pinecone, Zilliz Cloud) excel at low operations. Elastic/OpenSearch with k-NN is good when you want hybrid search alongside existing infrastructure. Vespa provides strong customization for ranking and relevancy scoring at scale.
On the model side, there are trade-offs between closed hosted models and open or hosted large models. The Megatron-Turing model family and other large foundation models offer strong capabilities for re-ranking and generation but often require significant GPU resources if self-hosted. Hosted assistants like Claude AI-powered assistants provide polished conversational behavior and safety features but come with constraints around data control and operational integration.
Case study snapshots
1) Enterprise legal search: A legal tech firm replaced keyword search with a hybrid system—vector index for semantic similarity plus a cross-encoder re-ranker. Result: 40% faster time-to-first-draft and a 25% reduction in manual review time. They invested heavily in provenance features to satisfy compliance audits.
2) Ecommerce product discoverability: An online retailer used embeddings to match user intent with product descriptions and combined that with a lexical filter for in-stock products. They prioritized p95 latency under 200ms to keep UI snappy during peak shopping hours. Caching common queries reduced model calls by 60% and saved costs.
Future outlook and standards
Expect more integration between model providers and vector platforms, tighter tooling for observability, and standards for provenance and safety. Industry attention on explainability and regulation (for example, the EU AI Act) will raise the bar for logging, risk assessment, and mitigation in production search systems. Open-source projects like FAISS, Milvus, and LangChain will continue to mature, while cloud providers add managed vector search and LLM orchestration services.
Key Takeaways
AI-driven search algorithms transform how teams retrieve and act on information, but they require deliberate engineering and governance. Start by defining SLOs, choose architecture patterns that match latency and control needs, instrument observability beyond system metrics to relevance signals, and plan deployments with cost-conscious scaling and data governance. Whether you use managed vector services or self-hosted stacks for specialized models like the Megatron-Turing model family, the operational design choices you make will determine reliability and business value. For conversational use cases, integrating Claude AI-powered assistants or similar hosted assistants can speed time-to-market—just balance that convenience against data control and regulatory requirements.
If you are setting up your first production system, treat it as a sequence of small experiments: tune embeddings and retrieval strategies, monitor user feedback, and expand generation capabilities only after you can measure and explain outcomes.